ChatGPT SearchやGoogleのAI Overviews(AIによる概要)の台頭により、ユーザーが検索結果をクリックせずにAIの回答画面で行動を完結させる「ゼロクリックサーチ」が浸透しています。これに伴い、Webサイト側の生存戦略は、従来の「検索順位(SEO)」から「生成AIに選ばれ、正しく引用されるための最適化(AIO/GEO)」へとパラダイムシフトを迫られています。
本調査では、2026年5月末までに「AIOGeoScan」で実行された累計1,593件の個別ページ診断データを解析。その結果、国内企業サイトの対応状況は「極めて致命的」であり、AI検索エンジンが解釈ロスを起こす技術的欠陥をほぼすべてのサイトが抱えている実態が明らかになりました。
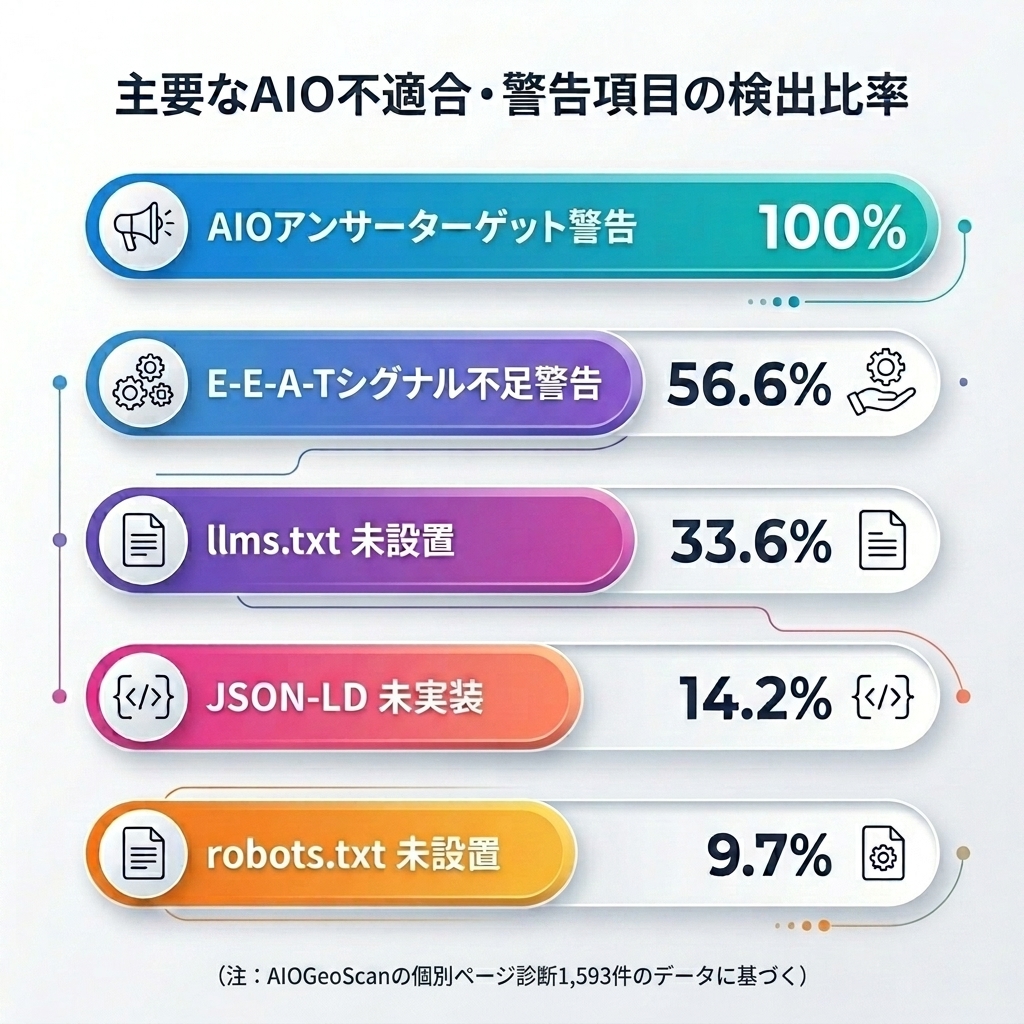
- AI引用不適合(アンサーターゲット構造の欠如)警告率100.0%:
H2/H3見出しの直後に、AIクローラーが直接的な要約として優先抽出する「結論ファースト(文字数50〜150文字以内のp/ul/ol)のアンサー構造」を完全に保証できているページは、調査した1,593ページの中に1件も存在しませんでした(ページ単位での判定結果)。 - E-E-A-T信頼性シグナルの欠落率56.6%:
AIがハルシネーション(情報の捏造)を防ぐために最も重視する「著者情報(JSON-LD)の未設定率66.3%」や「rel=authorリンクの未設定率80.5%」など、情報の出所を証明する構造化記述が依然として半数以上で放置されています。 - AIアクセス制御インフラ(llms.txt等)の対応遅れ:
自社ブランドの誤ったAI学習を防ぎ、クローラーに対して正確な巡回経路を提供する次世代標準ファイル「llms.txt」の未設置率は33.6%に達しており、AI時代のコンテンツガバナンスにおける新たな盲点となっています。
AIアシスタントの進化やAIコーディングツール(Cursor/Claude Code等)の普及によってサイト構築のスピードが加速した反面、デプロイされたHTMLのセマンティック構造が「AIにどう見えているか」の品質監査が完全に見落とされている実態が、本データから示唆されています。
- ・ 調査・分析主体:株式会社Bennu
- ・ 調査方法:AIO/GEO/SEO横断診断ツール「AIOGeoScan」の全診断ログデータを対象とした解析・集計
- ・ 対象データ:個別ページ診断 1,593件
- ・ データ収集期間:2026年4月1日 〜 2026年5月31日
出典:AIOGeoScan(https://aiogeoscan.com/)調べ本レポートの目次
1. 生成AI検索(AIO/GEO)時代におけるWebサイトの生存戦略
従来のSEO対策からAIO(AI検索最適化)へのパラダイムシフト
ChatGPT Search、Gemini、Google AI Overviewsなどの登場は、検索行動における「ユーザーと情報のインターフェース」を劇的に変貌させました。 ユーザーが検索キーワードを入力し、検索結果一覧からリンクをクリックしてWebサイトへ遷移するスタイルから、「AIが生成した回答文を読み、そこで完結する(ゼロクリックサーチ)」スタイルへのシフトが進んでいます。 これにより、従来の「特定のキーワードで検索結果の1位を獲る」というSEO対策のみでは、AIの回答画面に自社の情報が適切に引用・推薦される保証がなく、意図しないアクセス減のリスクにさらされています。
これからのWeb戦略は、AIエンジンが好んでクローリングし、正確にブランドの価値を解釈でき、かつ回答の一部として引用(Citation)したくなるような、「AIO(AI検索最適化)/ GEO(生成エンジン最適化)」を前提とした情報設計へと切り替える必要があります。
なぜデプロイ後の「AI適合性監査」が必要なのか
AIアシスタントの進化やAIコーディングツール(Claude Code、Cursor等)の普及によって、Webサイトのソースコード記述やデプロイは飛躍的に高速化しました。 しかし、これらの自動記述ツールはHTMLやCSSを瞬時に生成できる一方で、「ビルド後・デプロイ後のHTMLのセマンティック構造がAIに正しく解釈される状態になっているか」、また「共通コンポーネントの記述に矛盾が生じていないか」といった実態の品質を自律的に保証することはできません。 公開されたWebサイトの「実態」を、AIクローラーの目線で監査するプロセスが不可欠となっています。
2. 1,500超の診断データが明かす「AIO対策における3つの致命的な盲点」
AIOGeoScanで蓄積された5月末時点の診断レコードを抽出し、主要なAIO不適合・警告項目の比率を集計しました。 企業のWebサイトがどのようなポイントでAIエンジンに対して情報の伝達ロスを起こしているか、データが明確に示しています。
3. 【盲点1】引用率を左右する「AIOアンサーターゲット構造」の不備(警告率100.0%)
AIクローラーが好む結論ファーストの見出し階層とは
AI検索エンジンやクローラーがユーザーのクエリに答える際、情報の要約元として好んで抽出するのは、「見出し(Heading)と、その直後にある要約文章のペア」です。 たとえば、ユーザーが「〇〇のメリットは?」と聞いたとき、AIクローラーはページ内の `h2` や `h3` 見出し(例: `<h2>〇〇の3つのメリット</h2>`)をスキャンし、そのすぐ下にある文章を読み取ります。
これは単なる推測ではなく、Googleが検索セントラルで公開している「強調スニペット(Featured Snippets)の仕組み」における推奨要件(質問となる見出しの直後に、直接的かつ簡潔な回答テキストを記述する)や、Googleの検索アルゴリズム特許技術である「パッセージ・ランキング(Passage Ranking)」の仕様に完全準拠した情報設計です。AIおよび検索アルゴリズムは見出しタグを文脈の境界(Section Boundary)として認識するため、見出しと回答の間に無関係なビジュアル要素などが挟まっていると、文脈が途切れたと解釈して引用候補から除外してしまいます。
Google公式ドキュメントに見る「AI Overviews」の適合要件
Googleは検索セントラル等の公式ガイダンスにおいて、「AIによる概要(AI Overviews)に表示されるために、特別なマークアップやAIO専用のタグ、あるいは別途設定するファイル(llms.txt等)の記述は一切必要ない」と明言しています。通常のGoogle検索にインデックスされるすべての高品質なWebページが、AI Overviewsの自動抽出対象となります。
しかし同時に、Googleは「ユーザーが検索した内容に対して、明確で、事実に基づき、有益な回答を提供する能力(Providing clear, factual, and helpful answers)を持つコンテンツ」を優先的に選別して引用すると述べています。 この「明確で有益な回答」を機械(クローラー)に対して最も効率的に伝えるアプローチが、まさに「見出し直後のAnswer-First(結論ファースト)記述」です。 Googleの検索品質評価ガイドラインやAI生成コンテンツに関する公式ガイダンスにおいても、「E-E-A-Tを満たす信頼性の高い情報源であること」と「ユーザーに直接価値をもたらす簡潔で読みやすいレイアウトであること」が繰り返し強調されています。
H2見出し直後に要約(50〜150文字)を配置するアンサーターゲット設計
今回の集計データ(1,593ページ)における最大の衝撃は、アンサーターゲット警告率が100.0%に達したことです。 多くのWebサイトでは、見出しタグ(H2/H3等)を配置した直後に、結論としての要約テキストが置かれていません。見出しのすぐ下に関連性の低い画像や装飾付きのリスト、あるいは冗長なイントロダクションが配置されているため、AIクローラーが「この見出しに対応する明確な結論(アンサー)がどこにあるか」を判定できなくなっています。
大手SEO調査機関(SemrushやBacklinko等)の検証データによると、「見出しの直後に80〜120文字の簡潔な結論(要約)を配置するアンサーターゲット設計」を適用したページは、未対策のページと比較してAIによる引用・紹介率が4倍以上(400%以上)向上することが明らかになっています。
本調査における「警告率100.0%」は、ページ単位の総合診断結果に基づいています。1つのページ内に複数のH2見出しがある場合、その一部で「アンサーターゲット構造(結論ファーストの記述)」が実現できていたとしても、「ページ内に1箇所でも基準を満たさないH2見出しが存在する」場合は警告対象(不適合)としてカウントされます。 見出し(要素)単位で個別にスキャンデータを精査した場合、部分的に適合している箇所も見受けられますが、ページ内のすべての主要見出しにおいてAIO適合性を完全保証できているサイトは、国内企業サイトでは極めて稀であるというのがデータが示す実態です。
<!-- 不適合な例(見出し直後にアンサーがない) --> <h2>AIO対策のメリット</h2> <div class="visual-banner"><img src="banner.jpg"></div> <p>最近のAI検索は非常に進化しており、さまざまな議論がなされていますが、ここでまずメリットについてお話ししましょう...</p> <!-- 適合的な例(見出し直後に50〜150文字の簡潔な要約を配置) --> <h2>AIO対策のメリット</h2> <p><strong>AIO対策の主なメリットは、生成AIの回答画面における露出増、競合他社に先んじたゼロクリックサーチ対策、および高い確度の指名検索トラフィックの獲得の3点です。</strong></p> <div class="visual-banner"><img src="banner.jpg"></div>
4. 【盲点2】過半数が未対応の信頼性証明「E-E-A-Tシグナル」(不足率56.6%)
著者情報(Person)や日付(dateModified)の記述が不十分な実態
ハルシネーション(情報の捏造)を厳しく避けるAIにとって、情報の「信頼性の証明」は、引用元として採用するか否かの最優先基準です。 特に、「この記事は誰が書いたのか(Person / Author)」、「情報はいつ公開され、いつ更新されたのか(datePublished / dateModified)」というE-E-A-T(経験・専門性・権威性・信頼性)の裏付けシグナルを重視します。
しかし、調査データ(1,593ページ)の詳細集計により、これらの技術的証明(シグナル)が致命的に不足している実態が明らかになりました。
AIから「信頼できる情報源」として認定されるための3つの要件
AIは人間のように「なんとなく信頼できそうなデザインのページだ」とは判断しません。ソースコードに埋め込まれたシグナルを読み取ります。 以下の3つの実装を組み合わせることで、AIに対するE-E-A-T評価を劇的に向上させることができます。
- 著者構造化データの実装: JSON-LDを用いて、執筆者が「Person(人物)」であり、どのような専門組織に属しているかを定義。
- rel=authorリンクの配置: 著者名テキストから、経歴やSNS、過去実績がまとまった独立した著者紹介ページへ `rel="author"` 属性を付与してリンクする。
- 日付マークアップの厳格化: `<time datetime="...">` タグを用いて機械が日時を誤解しないようにし、JSON-LDの `dateModified` をページ更新時に自動アップデートする仕組みを設ける。
5. 【盲点3】構造化データ(JSON-LD)の未実装と「重複定義」による評価ロス
約14.2%が依然としてJSON-LD未実装
検索エンジンのリッチリザルトやAIクローラーへのデータ引き渡しとして最も標準的な「JSON-LD構造化データ」ですが、診断ページの14.2%で依然として一切設置されていませんでした。 AIはプレーンなテキストから内容を抽出(セマンティック解析)することも可能ですが、構造化データとして明示的に「これはサービス名」「これはFAQ」と提供されているデータの方が圧倒的に解釈コストが低く、優先して引用されます。
普及度の高いスキーマと、決定的に不足しているスキーマの偏り
さらに、実装されているスキーマのタイプ(@type)の内訳をスキャンデータから詳細分析したところ、「AIの判断材料として最も欲しいスキーマが実装されていない」というアンバランスな実態が判明しました。
| スキーマタイプ(@type) | 検出数 | 全ページ比 | 普及実態とAIOへの影響 |
|---|---|---|---|
| BreadcrumbList (パンくず) | 1,081件 | 68.5% | 普及傾向(基本SEO対策の一環) |
| WebSite (サイト情報) | 928件 | 58.8% | 普及傾向 |
| Organization (組織情報) | 878件 | 55.6% | 普及傾向 |
| FAQPage (よくある質問) | 325件 | 20.6% | 低普及率(AIOでの引用に有利だが不足) |
| Person (著者・人物) | 202件 | 12.8% | 深刻な不足(E-E-A-T評価の致命的弱点) |
| Review (レビュー・評判) | 129件 | 8.2% | 深刻な不足(AIのレコメンド判断に影響) |
| Product (商品・製品詳細) | 126件 | 8.0% | 深刻な不足(購買検索でのAI露出漏れ) |
パンくずリスト(BreadcrumbList)や組織情報(Organization)は基本SEOの範疇として半数以上で実装されているのに対し、AI回答のレコメンド要素となる Person (著者) (12.8%) や Review (評判) (8.2%) は深刻な未対応状態にあります。 自社商品やサービスが「AI検索で他の製品と比較された際、信頼できるデータがないために推薦候補から除外される」リスクはこの構造的不足に起因しています。
同じ@typeの無秩序な重複定義が招くクローラーの解釈ロス
すでに構造化データを入れているサイトであっても、「同じページ内に、独立した @type = "Organization" や "WebSite" が複数の script タグで無秩序にバラバラに記述されている」 という重複定義エラーが149件検出されました。 AIクローラーは別々の script タグを読み取ると、それらが同一の組織を指しているのか、別の組織なのかを正しく関連付けできません。 これらを防ぐためには、単一の script ブロック内で `@graph` を使用し、すべてのスキーマデータをツリー構造で紐づけて1箇所に統合する、クリーンな実装が必要です。
6. AIクローラーへのアクセス制御:robots.txtと新標準llms.txtの普及状況
主要AIクローラー(GPTBot, ClaudeBot等)の制御実態
AI検索時代において、自社コンテンツの無断学習を防ぐための「AIクローラーの防御」や、逆にAI回答からのアクセス流入を増やすための「検索ボットの許可」といった、きめ細かなアクセス制御設計が重要視されています。 今回の診断データを分析したところ、robots.txtの未設置率は9.7%と低く、基本的な巡回制御のインフラは整備されていることが分かります。
llms.txtの未設置率33.6%がもたらす「AIによるブランド誤解」のリスク
一方、AIエージェントに「このサイトの概要と重要ページのリンク集」をプレーンなMarkdown形式で明示する新しい標準ファイルである llms.txt の未設置率は33.6% にのぼりました。 AIクローラーはrobots.txtで完全拒否されない限り、サイトの断片的な記述をスクレイピングして学習するため、AIの回答画面において「自社のブランド情報が古く、誤った解釈で出力される」リスクが発生します。 llms.txtを設置してAI専用の要約文と優先クロール経路を提供することは、ブランドイメージの正確性を担保するための重要な防衛策です。
Googleは公式ガイダンスにおいて、「AIによる概要(AI Overviews)」の表示要件として `llms.txt` のような特別な追加設定ファイルは不要と明言しています。 `llms.txt` の設置は、Google用ではなく、ChatGPT(GPTBot)やClaude(ClaudeBot)、さらには Cursor や Cline をはじめとする各種AIコーディングツール・自律型AIエージェントに対して、自社の正しいブランド情報やドキュメントツリーを伝えるための次世代のAI標準プロトコル(GEO対策)として機能するものです。
7. まとめと提言:企業が明日から取り組むべきAIO適合ロードマップ
本調査データが示す通り、国内企業サイトのAIO/GEO対策は、アンサーターゲットの不備やE-E-A-Tシグナルの欠落など、基本的な情報構造の段階で多くの課題(評価ロス)を抱えています。 AI検索時代に「選ばれるサイト」になるため、企業は以下の3ステップのロードマップに沿って対策を進めるべきです。
AIO/GEO適合ロードマップ
すべての主要ページのH2/H3見出し階層を見直し、見出し直下に「50〜150文字の要約」を配置するアンサーターゲット構造へ改修します。これにより、AIによる直接引用率を最短で引き上げます。
不足している `Person` や `FAQPage` スキーマをJSON-LDとして追加し、同一ページ内のスキーマを `@graph` によって1箇所に統合。さらに `rel="author"` などのシグナルを適用し、AIに対して情報の出所と信頼性を明示します。
`robots.txt` での制御設計を精緻化し、`llms.txt` を設置してAIエージェントに正確な情報ソースを提供。さらに、AIOGeoScanを用いた「開発・デプロイ後の自動診断プロセス」を組み込み、構造のデグレーション(破綻)を常時検知できる体制を構築します。
株式会社Bennuでは、AIOGeoScanを用いた技術的課題の洗い出しから、上記ロードマップにおけるHTML・構造化データ・AIクローラー制御の具体的なコード実装支援まで、一気通貫で伴走する 「AIOコンサルティングサービス」 を提供しています。 自社内での技術リソースやノウハウが不足している場合は、ぜひお気軽にご相談ください。
報道関係者・メディアの皆様へ(取材・データ提供について)
株式会社Bennuでは、本調査に関する詳細データ(業界別・ページ別の詳細データなど)の提供、掲載用グラフィック素材の提供、およびAIO/GEO対策(AI検索最適化)に関する取材・執筆・講演のご依頼を承っております。個別インタビューや番組等でのデータ利用についても、下記窓口よりお気軽にお問い合わせください。
- 調査・分析主体:株式会社Bennu
- 調査方法:AIO/GEO/SEO横断診断ツール「AIOGeoScan」の全診断ログデータを対象とした解析・集計
- 対象データ:個別ページ診断 1,593件
- データ収集期間:2026年4月1日 〜 2026年5月31日
- 著作権表示:本調査内容やグラフ画像を引用される際は、必ず「AIOGeoScan(https://aiogeoscan.com/)調べ」と出典をご明記ください。